AI のニュース

AppleがWWDCで巻き返しを図る
AppleはWWDCの基調講演の大部分を、改善、パフォーマンス向上、長年求められていた機能の紹介に費やし、その後、アップグレードされたAI対応のSiriを発表しました。これは、同社がAIをソフトウェア全体の改善に向けた幅広い取り組みの一部として、ユーザーに認識させたいという意向を示しています。
出典: TechCrunch AI

OpenAIがIPOに向けて申請、Anthropicに続く
OpenAIは月曜日、過去1年近くにわたってライバルのAnthropicと競い合ってきたIPO競争における予備段階を完了した。同社は米証券取引委員会にForm S-1を機密裏に提出したことを発表した。これはAnthropicが6月1日に同様の手続きを行った決定に続くものである。
出典: The Verge AI

Amazon SageMaker AIとFHEによるエンドツーエンド暗号化ML推論
本ブログではこれまでML推論向けのFHE(完全準同型暗号)について「Amazon SageMakerエンドポイントで安全でリアルタイムな推論を実現する完全準同型暗号の有効化」という記事で論じてきたが、本稿はさらに一歩進めたものである。前の記事ではSEALという低レベルライブラリを使用して線形回帰アルゴリズムを手動で実装することでFHEベースの推論を「ゼロから」実装する方法を示していた。
出典: AWS Machine Learning Blog

ノートパソコンを閉じても安心:Amazon Bedrock AgentCoreでコーディングエージェントをホスト
Amazon Bedrock AgentCore Runtimeは、各エージェントセッションに独立したマイクロVMと永続的なワークスペース、Gatewayを通じた安全なツールアクセス、組み込み型のオブザーバビリティを提供します。これにより、Claude Code、Codex、Kiro、Cursorを秘密情報、ポート、ファイルシステムを共有することなく並行して実行できます。
出典: AWS Machine Learning Blog

AppleはAIを使用してSafariの拡張機能の問題を解決している
AppleはAIを使用してSafariの最大の弱点の1つを解決しようとしている。Safariは長年にわたり、主にAppleの厳格な開発要件により、ライバルブラウザが備えているような充実した拡張機能ライブラリが不足していた。
出典: The Verge AI

WWDC 2026: シリのAI、iOS 27、Apple Intelligenceなど発表内容まとめ
Appleの年次開発者会議WWDC 2026は、米国太平洋時間の午前10時にApple Parkで開幕し、シリ、iOS 27、Apple Intelligenceなど多くの発表が予定される1週間がスタートした。開発者向けイベントやデモンストレーションも予定されている。今年の開催は特に注目される。
出典: TechCrunch AI

マイク不要でAmazon Nova Sonicの音声エージェントを大規模に評価する
このポストでは、システムプロンプトとツール設定の調整を高速に反復できるツール(会話を実行し、結果を確認し、調整を繰り返す)として機能し、音声エージェントの品質を大規模に検証する包括的な評価フレームワークとして設計された、オープンソースフレームワークであるNova Sonic Test Harnessについて説明します。
出典: AWS Machine Learning Blog

Amazon Quick ARN: クロスアカウント移行と名前空間権限
この記事では、Amazon Quick ARNの構造をカバーし、それらを操作するための実践的なメンタルモデルを提供します。最後には、ARNを見てそれが移行戦略に何を意味するかを即座に理解でき、権限の問題をより迅速に診断でき、マルチテナントアーキテクチャを自信を持って設計できるようになります。
出典: AWS Machine Learning Blog

アメリカの労働力アカデミー:未来は万人のものへ
Metaは全国的に、熟練した職人技のキャリアへ参加者を迅速に導くために設計されたプログラムであるAmerica's Workforce Academy(AWA)を立ち上げています。
出典: Meta AI

ヨーロッパのAI柔軟性を解放:EUデータ処理とモデルアクセスのためのクロスリージョン推論ガイド
最新の生成AIモデルと高性能なアクセラレーテッドコンピュートへのアクセスが世界的に高い需要がある中、AWSの顧客はセキュリティとプライバシー要件を満たしながら、複数のAWSリージョンにおけるモデルの利用可能性と容量を活かすためのツールが必要です。
出典: AWS Machine Learning Blog

CrowdMath: クラウドソーシングされた数学研究討論のデータセット
大規模言語モデルは数学的推論において大きな進展を遂げていますが、既存のベンチマークは最終答案、段階的な解法、または完全な証明といった確定的な問題を評価するのが一般的です。本研究は、参加者が部分的な議論を提案し、先行する段階の不備を特定し、不完全な推論を修正し、段階的な貢献を徐々に統合していくという、協調的なオープン問題解決のプロセスをとらえた新しいデータセット「CrowdMath」を紹介します。これはMIT PRIMES--Art of Problem Solving (AoPS) CrowdMathプログラム(2016-2025)から164個の専門家による注釈付きの進捗チェーンで構成されており、その討論は査読済み論文に至っています。各チェーンはオープン問題の陳述から完成した証明まで、複数の参加者によるフォーラム討論の過程を追跡しています。投稿は部分的進捗、証明の完成、誤った推論、誤りの特定を含む、進化する解答プロセスにおける機能的役割によってラベル付けされています。
出典: arXiv cs.AI

CAF-Gen:議論構造を充実させるためのマルチエージェントシステム
自然言語テキストから複雑な推論を形式化することは、計算言語学における中心的な課題である。現在の議論マイニング技術は基本的な主張と前提を識別するが、前提のタイプ、証明基準、議論スキームなどの特徴を組み込むカーネアデス議論枠組み(CAF)といった高度なスキーマが必要とする豊かな構造情報を捉えるのに苦労している。本研究は、浅い議論構造をCAF準拠の議論モデルに充実させるために設計された自動マルチエージェントフレームワークCAF-Genを導入することでこの制限に対処している。反復的なクリエイター・レビュアーパイプラインを採用することで、クリエイターエージェントの出力は批評的エージェントによって検証され、構造的整合性が確保される。このマルチエージェント協働は、単一パス生成モデルに典型的な構造的不安定性を軽減するために重要である。実験結果は、反復的なフィードバックループが結果データの品質を向上させ、元のアノテーションとの強い一致を達成しながら、構造的により豊かなモデルを生成することを示している。
出典: arXiv cs.CL

「人を採る前に、AIに任せる」という新常識。専門知識ゼロ・最短10分で“もう一人の社員”をつくれるノーコードAIエージェント「WellSkate AI」提供開始 【本日より無料診断受付!】
労働力不足に対応する新たな戦略として、採用の前にAIを導入する企業が増えています。ノーコードAIエージェント「WellSkate AI」は、専門知識がなくても最短10分で業務自動化ツールを構築できるプラットフォームとして提供が開始されました。大規模言語モデルの普及により、AIの構築コストが大幅に低下し、中小企業でも導入が容易になったことが背景にあります。請求書処理や顧客対応メールなどの定型業務を自動化できることで、人的資源をより高度な業務へシフトさせることが期待されています。
出典: PR TIMES

HKJudge:香港判決文の法的言説注釈付きコーパス - 裁判所の判断根拠、推論過程、判決内容の解釈
本研究は、香港の判決文に対する言説分析のための初めての専門家注釈付き法的言説コーパス「香港判決文言説データセット(HKJudge)」を紹介する。HKJudgeは香港の5段階の裁判所階級全体にわたる刑事判決を含み、約29万文、650万トークンから構成され、法言語学の専門家により完全に注釈付けされている。2層構造の言説スキーマを設計し、裁判所が認定した事実、推論過程、判決内容を捉える。文レベルでは各文に26の修辞的役割のいずれかが割り当てられ、スパンレベルでは有罪判決要素(罪状、懲役期間、罰金)でさらに注釈付けされている。10人の法言語学注釈者によるアノテーションは高い一致度(κ = 0.8)を達成している。HKJudgeに対して修辞的役割分類と法的要素抽出の2つのタスクを定式化し、4つのBERTベースモデル、2つのオープンソースLLM(ゼロショットおよびファインチューニング設定)、および4つの商用LLMについて初の基準評価を提供している。この研究は、文レベルの言説注釈が香港判決文の構造モデリングに価値があることを実証し、法的判決予測に関する将来の研究のための豊富なデータ基盤を提供する。
出典: arXiv cs.CL

DiBS: 拡散モデルに基づく分枝選択
数独は厳密な離散制約の下での全体的な構造推論を必要とする制約充足問題の代表例である。既存の数独求解アプローチは従来的ヒューリスティックと深層学習ソルバーの2つが主流だが、学習ベースのソルバーは厳密性の保証が欠け、完全な記号的ソルバーは長尾探索に弱いという補完的な限界を抱えている。これらの問題に対処するため、分枝選択探索プロセスのガイドとして拡散モデルを活用したDiBSと呼ばれる新しいアプローチを提案する。DiBSは記号的ソルバーの完全性を維持しながら、拡散モデルを分枝順序付けの指針として使用する。核心的な手法は現在の部分割当と軽量の一貫性信号の下で候補値をランク付けすることである。さらに、その動作原理と有効性に関する詳細な理論的証明を提供する。困難なRoyle 17ヒント数独ベンチマークの実験結果は、DiBSが特に探索ノード数、バックトラック回数、長尾パーセンタイルにおいて強力なヒューリスティックベースラインと比較して探索コストを大幅に削減することを示している。また、分枝順序の誤りが最も高くつく困難なインスタンスにおいて、学習された全体的ガイダンスが有効であることが確認されている。
出典: arXiv cs.AI

加速フーリエSAT(AFSAT):GPUベースの対称疑似ブール充足可能性ソルバーの完全実現
連続局所探索(CLS)に基づく疑似ブール充足可能性問題向けのGPU加速ソルバーであるAccelerated Fourier SAT(AFSAT)を提案する。AFSATは概念実証的なアプローチであるFastFourierSATを完全に実装されたソルバーへと発展させ、単一の問題インスタンス内で任意の異種対称制約タイプおよび長さの混合に対応する。JAXコンパイラを使用し、AFSATは純粋関数合成、自動ベクトル化、自動微分、ジャストインタイム(JIT)コンパイルを活用して、候補割り当てのバッチ全体で大規模並列CLSを実行する。概念実証と比較して、数値安定性、実行時性能、メモリ効率の大幅な改善を実証する。メモリレイテンシおよび浮動小数点表現から生じる様々な制限を特定・対処し、自動並列化とコンパクト表現を活用することで実現している。浮動小数点の本質的な表現および安定性の制限は、カスタマイズされた離散フーリエ変換実装により部分的に対処される。JAXアレイシャーディングを通じて複数のアクセラレータにスケーリングする際に、ほぼ線形のスループットを達成する。
出典: arXiv cs.AI

Lean4Agent: エージェントワークフロー及び軌跡の形式的モデリングと検証
大規模言語モデル(LLM)に信頼性の高い多段階ワークフロー実行能力を備えさせることはAIの中心的課題となっている。LLMのエージェント機能の最近の進歩にもかかわらず、ほとんどのエージェントシステムはワークフロー実行軌跡の仕様化、検証、デバッグのための形式的手法を欠いている。この課題は数学における長年の問題を反映しており、自然言語の曖昧性が形式言語開発の動機となっている。この範例に触発されて、我々は依存型形式言語Lean4を用いてエージェント動作をモデリング・検証する最初のフレームワークLean4Agentを提案する。Lean4Agentはエージェントワークフローの意味的一貫性を形式的にモデリング・検証し、実行時失敗の局所化を可能にする拡張可能なLean4ライブラリFormalAgentLibを立ち上げる。FormalAgentLibに基づいて、さらにLeanEvolveを開発し、ワークフローを改善してその能力を強化する。
出典: arXiv cs.AI

生成モデルが市場選別を通じて人間の時間的学習を蝕む
現代の生成モデルは、AGI前の段階で知識と文化生産に構造的なリスクをもたらすと主張する論文。人間の時間的学習(HTL)を、時間をかけて問題に継続的に取り組むことで蓄積される経路依存的な知識として定義する。生成モデルの出力がHTL集約的な作業と表面的に類似するようになり、出力が真の人間学習を反映しているかどうかの検証コストが期待される利益に比べて高くなる。検証の経済的正当性が失われると、評価者は生産方法に関わらず出力に報酬を与え、数年の学習に投資した制作者は生成コストがほぼゼロの出力と価格競争に直面する。この過程を価値の崩壊と呼び、コスト検査フレームワークを通じて形式化する。学術出版、法務実務、コンテンツプラットフォーム、ソフトウェアセキュリティの複数領域の証拠は、検証侵食の4段階に対応している。AI安全性の成功は無関係であり、より整列の取れたモデルは人間とAI出力の観察可能なギャップを縮め、ソース検証をより困難にし、個々のAI出力が改善しても、HTL集約的作業に対する競争圧力を強める。
出典: arXiv cs.LG
位置論文:「ポスプロで直すな」—AIの科学は訓練ダイナミクスを研究する必要がある
本位置論文は、AIに対する科学的理解とは何かを問う。モデルは静的なオブジェクトではなく、データ、目的関数、アーキテクチャ、最適化ダイナミクスによって形成される時間発展するプロセスのスナップショットである。しかし、AI研究の多くはモデルを固定的な産物として扱い、訓練後の振る舞いを分析するのみで、その出現理由を問わない。本論文は、AIの科学は事後的な修正を超えて、モデルの振る舞いを生み出す訓練ダイナミクスを研究する必要があると主張する。そのような科学は、段階的により強い形の理解をサポートすべきである:初期の訓練信号から結果を予測し、軌跡が誤った時に介入し、最終的には望ましい特性をより確実に生み出す訓練手続きを設計すること。スケーリング則は損失の予測を日常化させたが、課題は能力、偏り、ロバスト性、安全性関連の振る舞いにこの成功を拡張することである。本論文は科学の歴史と哲学に基づいた理論の要件を明示し、機械的解釈可能性、公平性、記憶化、単純性バイアスの進展を検討し、具体的な未解決問題を特定する。
出典: arXiv cs.AI

MacArena: オンラインmacOS環境でのコンピュータ利用エージェントのベンチマーク
コンピュータ利用エージェント(CUA)はビジョンと制御プリミティブを通じてグラフィカルユーザーインターフェース(GUI)を操作し、OSWorldなどの標準化されたオンライン評価ベンチマークにより能力が急速に進歩している。しかしmacOSは十分にカバーされておらず、既存の唯一のベンチマークmacOSWorldはApple Silicon互換性のないx86仮想マシンで動作する。本研究ではMacArenaを紹介し、50のアプリケーションにまたがる421の手動検証済みタスクからなるベンチマークで、OSWorldのキュレーション済みポート、macOSWorldのコンテンツ、および49の新しいmacOS固有タスクを組み合わせ、Apple Silicon上でAppleのネイティブ仮想化フレームワークで実行される。macOSはLinuxベースのベンチマークでは捉えられない独特のGUIチャレンジを提示し、評価結果から既存ベンチマークでの高いモデル性能は真のクロスプラットフォームGUI能力というより、タスク分布への馴染みを反映していることが示される。
出典: arXiv cs.LG

長時間タスク対応ウェブエージェントのためのシグナル駆動型観察
長期間のタスクを実行するウェブエージェントは、毎アクション時に数万トークンに及ぶDOMおよびアクセシビリティツリーを処理するため、文脈が段階的に劣化し、タスク完了前に推論能力が低下する。本論文は、観察頻度とアクション頻度の結合をアーキテクチャ上の誤りと主張する。言語モデルの全体読み込みよりも文書クエリが効果的という知見に基づき、Signal-Driven Observation(SDO)を提案する。SDOは専用のサブコールで完全なDOMを読み込むが、タスク関連の要素とそのセレクタのみを返し、URLの遷移、新たに表示される対話要素、アクション失敗、またはブラウザの外生イベントによってシグナル検出器が発動した場合にのみ再呼び出しされる。論文はSDOが引き起こす未解決の問題を概説し、観察圧縮をウェブエージェント設計の中核的アーキテクチャ決定として扱うよう提唱する。
出典: arXiv cs.CL

FAIR-Calib: 拡散大規模言語モデルの学習後量子化のためのフロンティア認識不安定性重み付け校正
拡散大規模言語モデル(dLLM)はトークンを反復的に精密化しますが、一度コミットすると取り消せないため、初期の決定が脆弱なまま残る「安定性遅延」が発生します。本研究では、学習後量子化(PTQ)エラーが境界線上の決定をライティングフロンティアで容易に翻してしまい、その後永久に固定・増幅されることを明らかにしました。これに対処するため、dLMM向けの2段階PTQフレームワークであるFAIR-Calib(フロンティア認識不安定性重み付け校正)を提案します。第1段階では全精度教師モデルを用いてフロンティアヒットとマスク段階の信頼性を組み合わせた位置事前分布を推定します。第2段階では、重み付けされた隠れ状態MSEを最小化するオフポリシーレイヤーごとの校正を実行し、高額なエンドツーエンド拡散ロールアウトを必要とせずに脆弱なフロンティア状態の保護を効果的に優先化します。さらに、重み付けされた目的関数を出力KLダイバージェンスの代理として理論的に正当化します。
出典: arXiv cs.LG

人々がAIに本当に求めるもの:選好の多様性をマッピング
大規模言語モデル(LLM)は人間のフィードバックからの強化学習(RLHF)を通じて調整されることが多いが、この方法には既知の制限がある。75カ国のPRISMデータセットから1,500件の自由記述回答を分析した結果、異なる人々がAIシステムに異なるものを求めていることが判明した。ほとんどの価値観は回答者の4分の1未満から要望されており、例外は「真実性」で49%である。同じ言葉でも異なる意味が隠されており、「真実性」の定義は引用元のある主張を求める人、専門家意見を求める人、非主流意見を求める人など、潜在的に相容れない認識論的基盤を示している。人間らしさやAIの安全装置などの機能は物議を醸しており、肯定する人と拒否する人に分かれている。さらに、現在の二値比較では捉えられない状況的区別(デフォルトで行うべきことと「要求された場合」)を人々がよく使用することも判明した。これらの知見は、現在の整合化実務における根本的な問題を明らかにしており、単一の報酬モデルでは複数の定義の「真実性」を捉えることができず、このような現象は認識論的暴力と特徴付けられている。
出典: arXiv cs.CL

ポリシー内蒸留によるデータ効率的な自己回帰型から拡散型言語モデルへの変換
本研究は、自己回帰言語モデル(ARLM)を拡散言語モデル(DLM)に変換する手法を検討している。先行研究では因果的注意機構を双方向注意に置き換えてDLM目的関数で訓練していたが、これは2つの分布シフトを引き起こす。1つ目は次トークン予測目的からDLM目的への移行により、ARLMが習得した知識が失われる可能性がある。2つ目は標準DLMが訓練と推論の不整合に苦しむ。著者らはこれらの課題に対処するため、オン・ポリシー拡散言語モデル(OPDLM)を提案する。OPDLMはオン・ポリシー蒸留(OPD)により訓練され、学生モデル(双方向注意を持つARL)が自身の軌跡を生成し、教師モデル(元のARLM)がこれらの軌跡上でターゲットロジットを提供することで知識を蒸留する。このアプローチにより、DLMの訓練推論不整合を排除しながら、元のモデルからの蒸留によりARLMからの知識保持を強化する。実験結果は、OPDLMが従来手法比で15倍から7,000倍少ない訓練トークンで、幅広いタスクで良好な性能を達成することを示している。
出典: arXiv cs.CL

低データ・高次元出力問題のためのガウス過程潜在因子回帰
科学分野では、少ない訓練例から高次元出力を予測する回帰タスクが頻繁に必要とされる。多出力ガウス過程は低データ体制で優れているが、通常は高次元出力に対応できない。PCA-GPなどの圧縮後予測パイプラインは高次元性を扱えるが、予測ではなく再構成に最適化された基底に依存している。このギャップに対処するため、ガウス過程事前分布から抽出した低次元潜在状態の線形ガウスデコーディングとして各出力を表現するモデルを提案する。デコーダの重みを解析的に周辺化することで、圧縮と予測を単一の目的関数に結合し、高次元出力に対応可能にした。このモデルをGaussian process latent factor regression (GPLFR)と呼ぶ。本研究では、ロッキータイプ系外惑星の全球気候モデルの初の空間分解エミュレータを構築することによってGPLFRを実証した。
出典: arXiv cs.LG
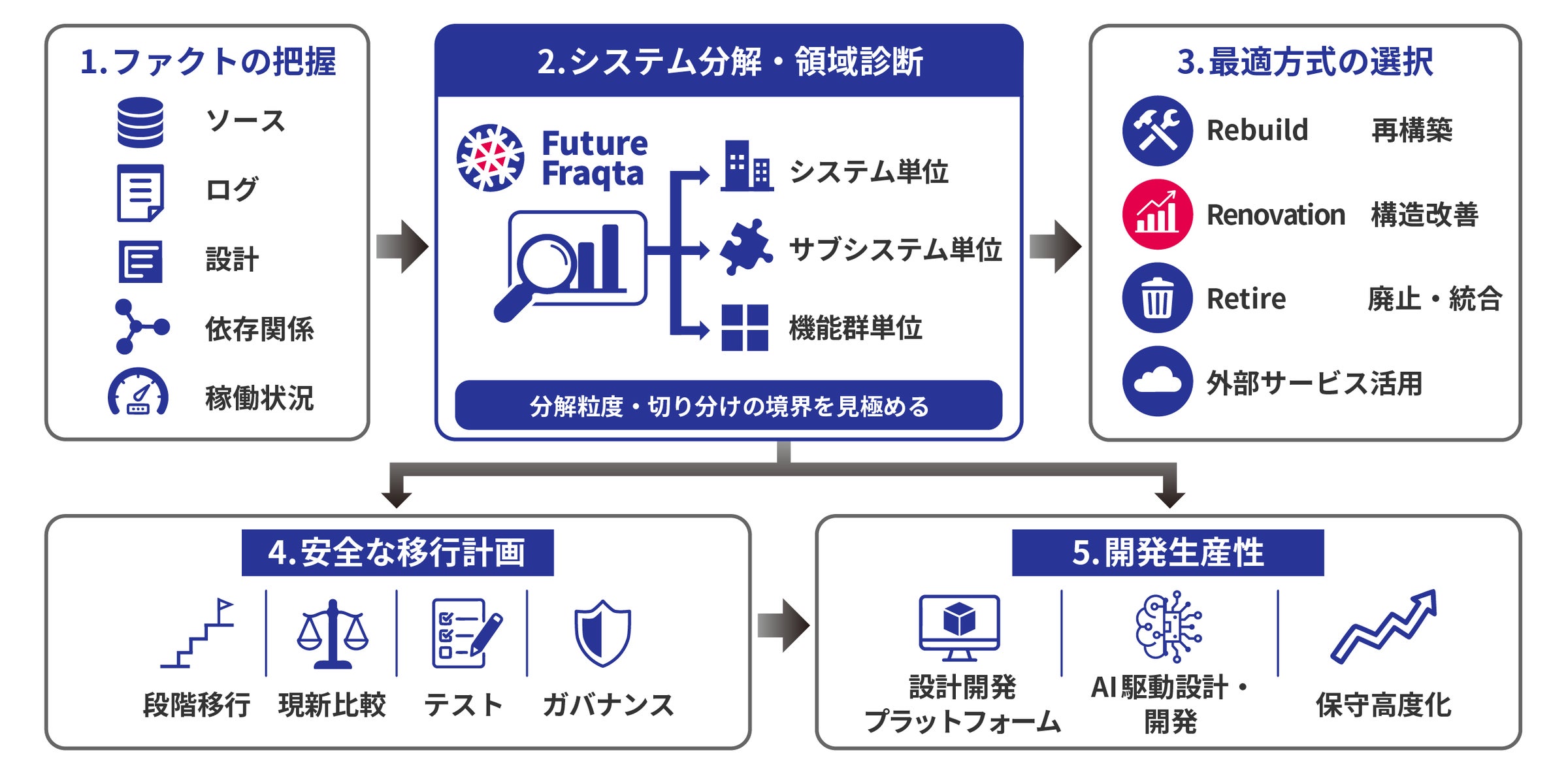
フューチャー、生成AI時代におけるレガシーシステム刷新プランを提供
多くの企業が1990年代から2000年代に構築したレガシーシステムを抱えており、保守コストの増加やセキュリティリスクが課題となっています。フューチャーは生成AIを活用した「漸進的モダナイゼーション」戦略を提供し、システムの段階的な現代化を支援します。生成AIはコードの自動分析やドキュメント化を助け、企業は従来の「破壊と再構築」に頼らない現実的な刷新が可能になります。ただし、AIが生成するコードは企業固有のビジネスロジックを完全には理解しないため、AIを人間の判断を支援するツールとして活用することが重要です。
出典: PR TIMES

LLM個人化における人間中心への再配置
大規模言語モデル(LLM)の個人化能力に関する評価のほとんどが合成データに依存している中、実際のユーザーに対する現在の個人化システムの有効性は不明である。本論文では、合成データと人間データを使用した場合のLLM個人化性能のギャップを調査する。550の人間会話と個人化の3段階にわたる判断を収集した:会話からのユーザー属性抽出(5,949の判断)、新しいプロンプトへの関連属性のペアリング(11,919)、個人化応答への関連属性の組み込み(1,101)。人間データの組み込みにより各段階でシステムの制限が明らかになった。モデルは人間会話から属性抽出に苦労し、関連属性に関する人間の判断と一致せず、個人化応答を生成する際は人間が汎用応答と同等以下と判定している(LLMは広くより良いと評価しているが)。最初の2段階で自動化個人化評価を人間データに近づけるための2つの軽量トレーニングベースの介入を導入する。しかし第3段階では、学習された報酬モデルが人間の評価とのみわずかな相関を達成するに過ぎず、人間に合わせた個人化品質判定を直接モデル化することが困難であることを示唆している。
出典: arXiv cs.CL

SafeGene: 転送可能な安全性アライメントのための再利用可能なアダプター
オープンウェイトLLMは、カスタマイズされたアシスタントへのファインチューニングが増加していますが、下流のファインチューニングにより安全性アライメントが弱まり、訓練データが意図的に有害でない場合でも、モデルが悪質なプロンプトに対して脆弱になる可能性があります。ターゲットモデルが新しいタスクデータやユーザーインタラクションで繰り返し更新されるため、反復的な安全性回復の問題が生じます。本論文では、各アーキテクチャ互換モデルファミリー内での横断的再利用のために設計された再利用可能な安全性アダプターモジュール「SafeGene」を提案します。安全性回復をモデル固有の修復ステップとして扱う代わりに、SafeGeneは安全性能力をタスク固有の更新から分離された独立した再利用可能なアダプター表現として扱います。この表現は、アラインされた-劣化したモデルの差分から取得され、データに対応したレイヤー選択を通じてタスク転送可能な安全性ベクトルに精密化され、各下流タスク適応モデルで少数ショットレイヤー単位の係数再キャリブレーションを通じて表現されます。
出典: arXiv cs.AI

深い表現学習の原理と実践:記憶の数学的理論
本書は、深層学習、特に生成モデルの時代において、大規模な生成モデルの訓練に多大な投資がなされている現状に対して、これらの「ブラックボックス」を理解することを目指している。深層ネットワークの内部メカニズムは不透明であり、解釈可能性、信頼性、制御の困難さにつながっている。本書は表現学習の観点から大規模深層ネットワークのメカニズムを解明することで、このブラックボックスを開こうとする試みである。表現学習は深層学習モデルの経験的力の重要な要因である。本書では、最適化と情報理論を通じてモダンなニューラルネットワークアーキテクチャの設計原理を説明し、アーキテクチャ開発を「錬金術」から大学初級レベルの線形代数と微積分の問題に還元する。また、これらの原理を応用して、効率的で解釈可能かつ制御可能でありながら、ブラックボックスモデルと同等かそれ以上の性能を持つ新しい手法とモデルを得ることについても論じ、深層学習の今後の方向性と表現学習の役割を探求する。
出典: arXiv cs.LG

対称性操作としての公平性を扱うことによるバイアスの検出と軽減
機械学習システムは高い経済的利害が関係する場面でしばしばバイアスを示す。本研究ではバイアスを対称性破れ操作として形式化し、分類器が敏感な属性を反事実的に切り替える操作の下で出力が不変であれば、その分類器は公平であると定義する。損失ベースの正則化を対称性復元メカニズムとして実装し、様々なレベルのノイズ、相関、バイアスを含む4つの合成データセット上で評価した。本フレームワークは90%以上の違反削減を達成し、精度低下は約5%である。このフレームワークは因果グラフの知識を必要とせず、計算量は少なく、ビット反転として定義可能な任意の敏感な属性に汎化可能であり、主流ベンチマークに欠落している局所的差別源が存在する文脈に適している。
出典: arXiv cs.AI

UnpredictaBench: LLMにおける分布的ランダム性を評価するためのベンチマーク
大規模言語モデル(LLM)が真の基礎分布をキャプチャする能力をテストする評価指標UnpredictaBenchが導入されました。LLMが経済シミュレーションなど他の主体の代替として使用される場合が増えていますが、多くのモデルが単一の尤もらしい答えに収束する傾向があり、実際のシステムの予測不可能性を捉えられていません。出力の多様性向上に関する最近の研究は不十分で、シミュレーションには単なるバリエーション豊かな出力ではなく、目標分布に校正されたサンプルが必要です。UnpredictaBenchは、正規統計分布、確率的プログラムによる分布、ランダムプロセスを記述する自然言語シナリオを含む448個の問題を提示し、コルモゴロフ・スミルノフ統計検定を用いてモデルの出力が目標分布にどの程度近いかを定量化するKS@Nという評価指標を導入しています。複数のオープンソースモデルと商用モデルをテストした結果、分布能力に大きなばらつきが見られ、サンプルサイズ100(標準指標KS@100)での得点は0近くから20%以上まで分布し、どのモデルもKS@100で40%を超える成績を達成できていません。
出典: arXiv cs.CL

一貫性駆動型強化学習による言語間事実的リコール性能の向上
英語データで主に学習した大規模言語モデル(LLM)は豊富な世界知識を保有していますが、他言語での信頼性のある表現に失敗することが多いという言語間事実的矛盾の問題に対処するため、本研究ではPolyFactという大規模並列多言語事実的質問応答データセットを導入しました。12の言語的に多様な言語にわたり、ウィキデータに基づく100Kの事実を含みます。PolyFactを用いて、Qwen-2.5-7BとOLMo-2-1124-7Bの言語間事実的リコール性能を改善するため、軽量継続的事前学習(CPT)、教師あり微調整(SFT)、およびグループ相対方針最適化(GRPO)を比較しました。GRPOは一貫してSFTを上回り、言語間の一貫性と未見言語への汎化性能を改善しますが、並列データへのCPTは限定的な追加利得しかもたらしません。機構的分析により、GRPOはMLP層とアテンションヘッドの言語特殊化を削減することで多言語ルーティングを再編成し、より共有された言語間表現を促進することが示されました。本研究ではコード、モデル、およびデータセットを公開します。
出典: arXiv cs.CL

エージェントAI制御評価における攻撃選択は安全性を大幅に低下させる
AI制御は、能力の高い信頼できないAIエージェントを、より弱い信頼できるモニターと限定的な人間監査予算の下で展開するための安全性フレームワークである。制御評価は、レッドチーム攻撃ポリシーをブルーチームモニターと対立させることでこれらのプロトコルをストレステストするが、現在の評価は通常、攻撃のタイミングを戦略的に選択しない攻撃者を想定している。本研究は、攻撃決定を攻撃開始時期を決定する開始ポリシーと進行中の攻撃を中止するかどうかを決定する停止ポリシーに分解することで、エージェント設定における攻撃選択能力を研究した。BashArenaとLinuxArenaの2つのエージェント設定において、両ポリシーは基礎となる攻撃能力を変えることなく、測定された経験的安全性を大幅に低下させた。監査予算1%の場合、開始ポリシーはBashArenaとLinuxArenaの両方で安全性を20ポイント削減し、停止ポリシーはBashArenaで20ポイント、LinuxArenaで28ポイント削減した。これらの削減は、攻撃選択の効果の上限として解釈されるべきである。
出典: arXiv cs.AI

言語モデルの失敗:確定的かつ持続的な推論失敗のトークンレベル特性
言語モデルの推論失敗は、推論トレース内で識別可能な特性を残す異なるプロセスを通じて発生する。本研究はトークンレベルの不確実性シグナルを使用してこれらの失敗を特性化し、経験的に区別可能な2つのプロセスから生じることを発見した。第1は確定的失敗で、モデルがトレース初期の不正な推論経路に固着する。中心的な診断特性は確定点であり、その先で追加のトークンを考慮すると失敗検出がむしろ悪化する。第2は持続的不確実性で、不確実性はトレース全体を通じて蓄積され、失敗と成功の完了を区別するには完全なトレースが必要となる。これらの特性は23のモデル-データセット構成で再現され、フレームワークの反証可能な予測は23例中20例で保持され、両方の失敗モードにおいて偶然を大きく上回る。最後に、自己一貫性への直接的な含意を示す失敗モードフレームワークを実証し、不確実性シグナルが補完するケースと選択的にスキップできるケースを特定する。これらの結果は、LLM推論失敗がいつ検出可能になるかを理解し、それに応じて検出戦略を適応させるための基礎を提供する。
出典: arXiv cs.CL

並列連続局所探索の研究
本研究は、対称的な疑似ブール(PB)制約を伴うブール充足可能性問題の解法アプローチとして、並列連続局所探索(CLS)を検討する。n変数のPB充足可能性問題は、n次元超立方体上の微分可能な目的関数を持つ連続最適化問題に緩和される。充足可能なインスタンスについて、この最適化問題の大域的最小化子はSAT問題の充足割り当てに対応する。経験的実験を通じて、以下の新知見を提示する:(i)冗長制約は収束を加速させるのではなく阻害する可能性がある、(ii)CLSはハイブリッド設定での部分ソルバーとして有望であり、部分割り当てを迅速に完成させる、(iii)鞍点密度の高い目的関数により局所探索はソリューション品質(充足度)の安定分布に急速に収束し、追加のソルバーステップは限定的な効果しか得られない。本知見は、現代のアクセラレータハードウェア上のSATに対するCLSの実践的利用に有用である。
出典: arXiv cs.AI

CARVE-Q: 量子提案、古典的に認証された対話型運転修復
本論文では、運転操作が拒否された後、その修復が安全規則、優先権、コスト配分、およびエゴフォールバックを尊重することを証明する必要があるという問題に対処する。CARVE(拒否操作の修復の認証付き低コスト包絡線)は、予測なしで対話型修復の証明書アーキテクチャを提供する。拒否操作が与えられた場合、CARVEは有限修復ラティスを構築し、バインディングルール、選択された共同修復、優先権スケーリング協力包絡線、責任加重コスト分割、およびエゴのみフォールバックを記録した構造化証明書を発行する。多所有者修復が積ラティスM = ∏_j |𝒜_j|を誘発することから、CARVE-Qは量子最小値探索を黒箱ラティスにのみ適用し、すべての安全権限は古典的なままとする検証者シールド量子AI探索層を導入する。古典的最小値探索がΘ(M)クエリを必要とするのに対し、Dürr-Hoyerおよびgrover最小値探索はO(√M)オラクルクエリを使用する。
出典: arXiv cs.AI

本当に確実ですか?シンボリック回帰における不確実性定量化の包括的かつ理解可能な調査
シンボリック回帰(SR)は、数学関数の空間を体系的に探索し、データセット内の基礎的な関係を正確に捉えるモデルを発見する手法のクラスです。この分野の最近の進展にもかかわらず、不確実性定量化(UQ)のサポート不足が現実世界の意思決定プロセスへの採用を制限しています。回帰分析では、UQはモデルの信頼性に関する重要な情報を提供し、データの不確実性を考慮することでオーバーフィッティングを回避し、意思決定に向けた洞察を提供するのに役立ちます。本調査は、この問題に初めて明確に対処するもので、シンボリック回帰におけるUQの本質的な概念を紹介し、現在の文献を頻度主義的、ベイズ的、モデル選択という3つの研究方向に広く分類してレビューしています。その重要性にもかかわらず、シンボリック回帰におけるUQはまだ十分に探索されていないため、シンボリック回帰のための信頼できるUQ手法の研究をさらに進めることが重要です。
出典: arXiv cs.LG

レイヤーをスキップするか、ループするか?LLMにおけるプログラム・オブ・レイヤーの学習
大規模言語モデル(LLM)は従来、固定の深さと順序で全レイヤーを非反復的に実行して推論を行う。本研究は、訓練不要で柔軟な動的プログラム・オブ・レイヤー(PoLar)が広く存在することを明らかにする。事前学習されたレイヤーをモジュールとしてパッキングしてスキップまたはループさせ、各入力に対してカスタマイズされたプログラムを形成できる。ほとんどの入力では、大幅に短いプログラム実行で同等以上の精度を達成でき、元のLLMの誤った予測も、より少ないレイヤーを持つ別のプログラムで修正できる。これらの観察は、推論が標準的なフォワードパスを超えた複数の有効な潜在計算を認めることを示唆している。実践的にPoLarを効率的に実現するため、軽量なPoLar予測ネットワークを提案する。このネットワークは各入力に対して事前学習されたレイヤーを動的にスキップまたは繰り返す実行プログラムの生成を学習する。数学的推論ベンチマークでの実験により、PoLarは標準推論および従来の動的深さ手法と比べて一貫して精度を改善し、多くの場合より少ないレイヤーを実行することを示す。
出典: arXiv cs.LG

【自治体AI zevo】Claude Opus 4.8 が本日2026年5月29日(金曜日)より利用可能に!新たな日本リージョンのClaude系の生成AIモデルを追加!
自治体向けAIプラットフォーム「zevo」に新型言語モデル「Claude Opus 4.8」が5月29日より利用可能になった。このサービスは地域課題の解決を目的としており、従来の中央集約型クラウドサービスから地方分散型へのシフトを示す重要な転換点となっている。地方企業による自治体固有のニーズに対応したAI活用モデルの開発が進む中、国際的な大型言語モデルのローカライズが加速し、AI産業のコモディティ化が進行している状況を反映している。
出典: PR TIMES

テラヘルツ双櫛分光法を用いたポリマー分類のための多スケール特徴注意ネットワーク
リサイクルプラスチックの品質と安全性を確保するためのポリマー識別は重要だが、従来の分別および分光技術は堅牢な判別をもたらすのに苦労している。テラヘルツ双櫛分光法(THz-DCS)は、迅速で高解像度かつ非破壊測定を提供する有望な代替手段となる。本研究では、THz-DCSを利用して純粋なポリマー、多層フィルム、商用ブレンド、およびバイオポリマーを含む12種類のポリマーを分類する。これらのスペクトル信号の複雑性に対処するため、THz-DCSデータ向けに設計された新しいディープラーニングアーキテクチャである多スケール特徴注意ネットワーク(MSFAN)を提案する。このフレームワークは信号再キャリブレーション用の特徴ゲーティングと多様な周波数パターンを捉えるための多スケール並列畳み込みを統合している。これらの特徴は交差特徴注意と注意プーリングを通じてさらに洗練され、モデルが最も有用なテラヘルツ領域を本質的に強調することを可能にする。MSFANは最先端モデルを一貫して上回り、85.2%の分類精度に達する。
出典: arXiv cs.LG

NotebookLMのGemini 3.5アップグレード、クラウドコンピュータと情報源検索機能を追加
Googleは「全面的な」アップデートをNotebookLMに展開しています。このAI搭載のノート作成アプリは、Googleの改良版Gemini 3.5モデルを使用するようになり、月曜日のブログポストによれば「より正確で信頼性の高い情報」で応答できるようになります。
出典: The Verge AI

OpenAI、Codexのビジネス用途を広げる役割別プラグインを公開、アノテーション対象拡大やSitesのプレビュー提供も
OpenAIは2026年6月2日、Codex向けに、職種や役割に合わせて使える6種類の新しい「役割別プラグイン」、成果物をWebサイトやアプリとして共有できる「Sites」のプレビュー提供、選択箇所を指定して修正を依頼できる「アノテーション」の対象拡大を発表した。
出典: gihyo.jp

すぐ知りたい「Microsoft Build 2026」まとめ ~Windows AI APIがGPUにも対応、RTX Spark搭載の開発用PC、ローカルSLM新モデル、エージェント前提の新デバイスなど/OpenClawも安全?なAI用サンドボックス、パーソナルエージェントも
Microsoftの開発者向けイベント「Microsoft Build 2026」が6月3日(米国時間)、米サンフランシスコとオンラインとで開幕した。
出典: 窓の杜

アマゾンがAI生成のカスタムマーチャンダイズを立ち上げ
Amazonは、Alexa for Shoppingを使用してAI生成デザインで作成したプリントオンデマンド機能を拡大しており、Tシャツ、ウォーターボトル、フーディーなどの商品に対応しています。
出典: The Verge AI

マイクロソフトのAI責任者、超知能は間近だが仕事は奪わないと述べる
本日はMicrosoft AIのCEOであるムスタファ・スレイマンと対談します。今回は冒頭を短くします。今週は妻の実家の農場から配信しており動画でもご確認いただけますが、今回は非常に濃い内容です。ムスタファの新人育成アプローチから様々なトピックをカバーしています。
出典: The Verge AI

進捗や目標を投入→AIが分かりやすいWebダッシュボードに、チーム間共有も OpenAI、Codexに新機能「Sites」
米OpenAIは6月2日(現地時間)、AIコーディングツール「Codex」の新機能「Sites」を発表した。生成したアイデアや成果物をWebサイトやアプリに変換し、URLでチームに共有できる。
出典: ITmedia NEWS 速報

Anthropicに続き、OpenAIが機密でIPO申請を提出
この申請は、主要なライバルであるAnthropicも上場を目指して申請してから1週間余り後に行われたもので、2つのAI企業間の競争が加速している。
出典: TechCrunch AI

AppleがSiri AIと次世代Apple Intelligenceを発表
Apple IntelligenceとスマートなSiriの計画を初めて発表してから2年後、WWDCでAppleは新しいAI機能とより賢く、より個人化されたSiriを発表した。
出典: The Verge AI

規模での優れた意思決定:数学的最適化が直感を上回る方法
本稿では、数学的最適化を紹介し、より広いAIの領域内での位置付けを説明し、Innovation Centerが顧客と協力して具体的な成果を実現した実際の成功事例を紹介します。
出典: AWS Machine Learning Blog

WWDC 2026: 視聴方法と期待できることを解説
アップルの年間最大イベントが間もなく開催される。Worldwide Developers Conferenceでは、iOS、macOSおよびアップルの他のすべてのオペレーティングシステムのアップデートが紹介され、今年のイベントではSiriの大規模なオーバーホールも含まれる可能性がある。
出典: The Verge AI

厳選ニュースメディアでPRを届けませんか?
News In Focus は、信頼できる媒体から「読む価値のあるニュース」を厳選配信する解説メディアです。経営者・専門職など質の高い読者層に、あなたのサービスを自然な記事として届けられます。
掲載プランを見る →
AI審査つき・最短当日公開のPR掲載
Claudeによる法令・品質の自動審査で、安心・スピーディーに掲載。PV・CTR・滞在時間をダッシュボードで可視化し、掲載効果を数字で確認できます。月額プランは¥80,000/月から。
料金プランを見る →